Spark - good practices: some common caveats and solutions
Spark is an open source scalable engine to process your data, whether in batches or real-time streaming.
It has become widely popular, however it can be also quite complex, and it takes time exploiting it correctly.
Here are below some common mistakes - and their solutions - and also some useful tips for making your work with Spark easier.
never collect a Dataset
Never collect - quoted from the Spark Scaladoc:
(collect) should only be used if the resulting array is expected to be small, as all the data is loaded into the driver's memory
ds.collect() // NOT OK - is long and has a good chance
// of crashing the driver, unless ds is small
ds.show() // OK - displays only the first 20 rows of ds
ds.write.parquet(...) // OK - saves the content of ds out into external storage
evaluate as little as possible
Quoted from the Spark Scaladoc:
Operations available on Datasets are divided into transformations and actions. Transformations are the ones that produce new Datasets, and actions are the ones that trigger computation and return results
(...)
Datasets are "lazy", i.e. computations are only triggered when an action is invoked
In other words, you should limit the number of actions you apply on your Dataset, since each action will trigger a costly computation, while all transformations are lazily evaluated.
Though it is not always possible, the ideal would be to call an action on your Dataset only once. Nevertheless, avoid calling an action on your Dataset unless it is necessary.
For example, doing a count (which is an action) for log printing should be avoided.
dsOut is computed twice in the exemple below:
case class Data(id: Long, desc: String, price: Double)
val ds = Seq(
Data(1, "a", 123), Data(2, "b", 234), Data(3, "c", 345),
Data(4, "a", 234), Data(5, "a", 345), Data(6, "b", 123),
Data(7, "a", 234), Data(8, "c", 345), Data(9, "a", 234),
Data(10, "b", 234)).toDS
val dsOut = ds.map({ line =>
line.copy(desc = s"this is a '${line.desc}'")
})
println(s"num elements: ${dsOut.count}") // first dsOut computation
dsOut.show // second dsOut computation
The simplest and preferable solution would be to skip the print, but if it is absolutely necessary you can use accumulators instead:
val accum = sc.longAccumulator("num elements in ds")
val dsOut = ds.map({ line =>
accum.add(1)
line.copy(desc = s"this is a '${line.desc}'")
})
dsOut.show // single dsOut computation
println(s"num elements: ${accum.value}")
avoid unnecessary SparkSession parameter
It is not necessary to pass the SparkSession as a function parameter if this function already has a Dataset[T] or DataFrame parameter. Indeed, a Dataset[T] or DataFrame already contains a reference to the SparkSession.
For example:
def f(ds: Dataset[String], spark: SparkSession) = {
import spark.implicits._
// ...
}
can be replaced by:
def f(ds: Dataset[String]) = {
import ds.sparkSession.implicits._
// ...
}
Similarly:
def f(df: DataFrame, spark: SparkSession) = {
import spark.implicits._
// ...
}
can be replaced by:
def f(df: DataFrame) = {
import df.sparkSession.implicits._
// ...
}
remove extra columns when mapping a Dataset to a case class with fewer columns
When a Dataset[T] is mapped to Dataset[U] (Dataset[T].as[U]), with U being a subclass of T with fewer columns, the resulting Dataset will still contain the extra columns.
Let’s illustrate this with an example:
case class Data(f1: String, f2: String, f3: String, f4: String)
case class ShortData(f1: String, f2: String, f3: String)
val ds = Seq(
Data("a", "b", "c", "d"), Data("e", "f", "g", "h"),
Data("i", "j", "k", "l")).toDS
ds.as[ShortData].show
// will output:
// +---+---+---+---+
// | f1| f2| f3| f4|
// +---+---+---+---+
// | a| b| c| d|
// | e| f| g| h|
// | i| j| k| l|
// +---+---+---+---+
We would have expected only columns f1, f2 and f3, but in fact, even the schema still contain the extra column f4!
ds.as[ShortData].printSchema
// will output:
// root
// |-- f1: string (nullable = true)
// |-- f2: string (nullable = true)
// |-- f3: string (nullable = true)
// |-- f4: string (nullable = true)
This is due to Dataset[T].as[U] type resolution being lazy. Adding a transformation (even a transformation doing nothing!) will force Spark to evaluate the type and fix the issue:
ds.as[ShortData].map(identity).show
// will output:
// +---+---+---+
// | f1| f2| f3|
// +---+---+---+
// | a| b| c|
// | e| f| g|
// | i| j| k|
// +---+---+---+
ds.as[ShortData].map(identity).printSchema
// will output:
// root
// |-- f1: string (nullable = true)
// |-- f2: string (nullable = true)
// |-- f3: string (nullable = true)
always specify schema when reading files (parquet, json or csv) into a DataFrame
Let’s begin with a Dataset mapped on case class TestData:
case class TestData(id: Long, desc: String)
import spark.implicits._
import org.apache.spark.sql.SaveMode
val ds = Seq(
TestData(1L, "a"), TestData(2L, "b"), TestData(3L, "c"),
TestData(4L, "d"), TestData(5L, "e")).toDS
ds.show
// will output:
// +---+----+
// | id|desc|
// +---+----+
// | 1| a|
// | 2| b|
// | 3| c|
// | 4| d|
// | 5| e|
// +---+----+
// save ds locally
val localFile = "file:///home/cpreaud/output/test_schema_change"
ds.repartition(1).write.mode(SaveMode.Overwrite).parquet(localFile)
Now let’s add a new field comment in case class TestData
case class TestData(id: Long, desc: String, comment: String)
We’re hitting an error when we try to map the parquet file loaded as a Dataset to the new definition of TestData, because the schema of the parquet file and the schema of TestData do not match anymore:
val dsRead = spark.read.parquet(localFile).as[TestData]
// will output:
// org.apache.spark.sql.AnalysisException: cannot resolve 'comment' given input columns: [desc, id]
// at org.apache.spark.sql.catalyst.analysis.package$AnalysisErrorAt.failAnalysis(package.scala:54)
// (...)
It works correctly if the schema is enforced when the parquet file is read:
import org.apache.spark.sql.Encoders
val schema = Encoders.product[TestData].schema
val dsRead = spark.read.schema(schema).parquet(localFile).as[TestData]
dsRead.show
// will output:
// +---+----+-------+
// | id|desc|comment|
// +---+----+-------+
// | 1| a| null|
// | 2| b| null|
// | 3| c| null|
// | 4| d| null|
// | 5| e| null|
// +---+----+-------+
avoid union performance penalties when reading parquet files
Doing a union to produce a single Dataset from several parquet files loaded as Datasets takes a lot more time than loading all the parquet files at once into a single Dataset.
Let’s load each parquet file into a Dataset and union all these Datasets to produce a single Dataset:
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.sql.Encoders
import SaleRecord
val fs = FileSystem.get(sc.hadoopConfiguration)
val saleSchema = Encoders.product[SaleRecord].schema
fs.globStatus(new Path("/path/to/sale/data/*/2022/202203/202203*"))
.map(_.getPath.toString)
.foldLeft(spark.emptyDataset[SaleRecord])((acc, path) =>
acc.union(spark.read.schema(saleSchema).parquet(path).as[SaleRecord])
).count
→ Took 12 min
Let’s have a look at the Spark UI for more understanding on what’s going on.
- the DAG for the union of Datasets is huge (the image below display only a small part of the DAG):
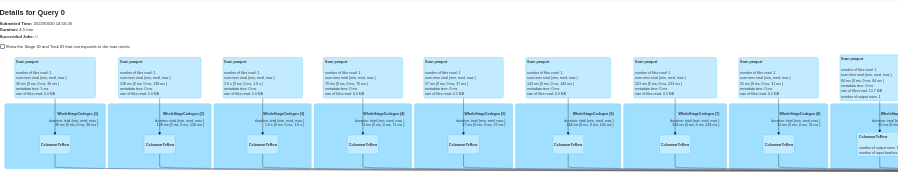
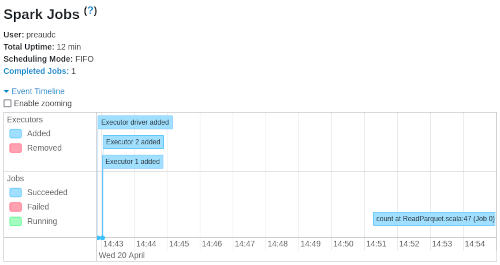
- analyzing this complex DAG takes time: there is a big pause at the start of the application:
Now let’s load all parquet files at once into a single Dataset:
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.sql.Encoders
import SaleRecord
val fs = FileSystem.get(sc.hadoopConfiguration)
val saleSchema = Encoders.product[SaleRecord].schema
val listSales = fs
.globStatus(new Path("/path/to/sale/data/*/2022/202203/202203*"))
.map(_.getPath.toString)
spark.read
.schema(saleSchema)
.parquet(listSales:_*)
.as[SaleRecord]
.count
→ Took only 2.1 min
The Spark UI confirms that things are better now.
- the DAG is very simple as you can see:
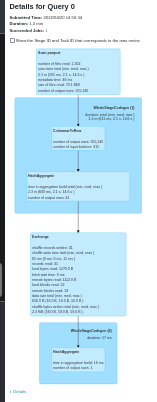
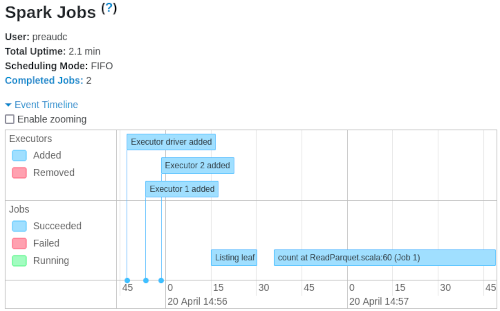
- there is no pause at the start of the application:
prefer select over withColumn when adding multiple columns
withColumn should be avoided when adding multiple columns. Quoted from Spark source code:
[`withColumn`] introduces a projection internally. Therefore, calling it multiple times,
for instance, via loops in order to add multiple columns can generate big plans which
can cause performance issues and even `StackOverflowException`. To avoid this,
use `select` with the multiple columns at once.`
Let’s illustrate this by adding columns to df:
val df = Seq((1L, "a"), (2L, "b"), (3L, "c")).toDF("uid", "desc")
df.show
// will output:
// +---+----+
// |uid|desc|
// +---+----+
// | 1| a|
// | 2| b|
// | 3| c|
// +---+----+
Add two columns “col1” and “col2” with withColumn:
df.withColumn("col1", lit("val1"))
.withColumn("col2", lit("val2"))
.show
// will output:
// +---+----+----+----+
// |uid|desc|col1|col2|
// +---+----+----+----+
// | 1| a|val1|val2|
// | 2| b|val1|val2|
// | 3| c|val1|val2|
// +---+----+----+----+
Add two columns “col1” and “col2” with select:
df.select((
df.columns.map(col(_)) :+ // get list of columns in df as a Seq[Column]
lit("val1").as("col1") :+ // add Column "col1"
lit("val2").as("col2") // add Column "col2"
):_* // un-pack the Seq[Column] into arguments
).show
// will output:
// +---+----+----+----+
// |uid|desc|col1|col2|
// +---+----+----+----+
// | 1| a|val1|val2|
// | 2| b|val1|val2|
// | 3| c|val1|val2|
// +---+----+----+----+
N.B.: always prefer the select implementation when adding multiple columns!
A few final words
Spark versatility comes with a certain level of complexity, I hope that this article will help you writing better applications.
About the author
Christophe Préaud is data architect at Verkor.
You can connect with him on LinkedIn.